
难点问题:
1.爬虫采集
url池,文章唯一性,Selenium渲染,多线程采集,xpath+jsoup自定义html解析器 jpath,多线程解析
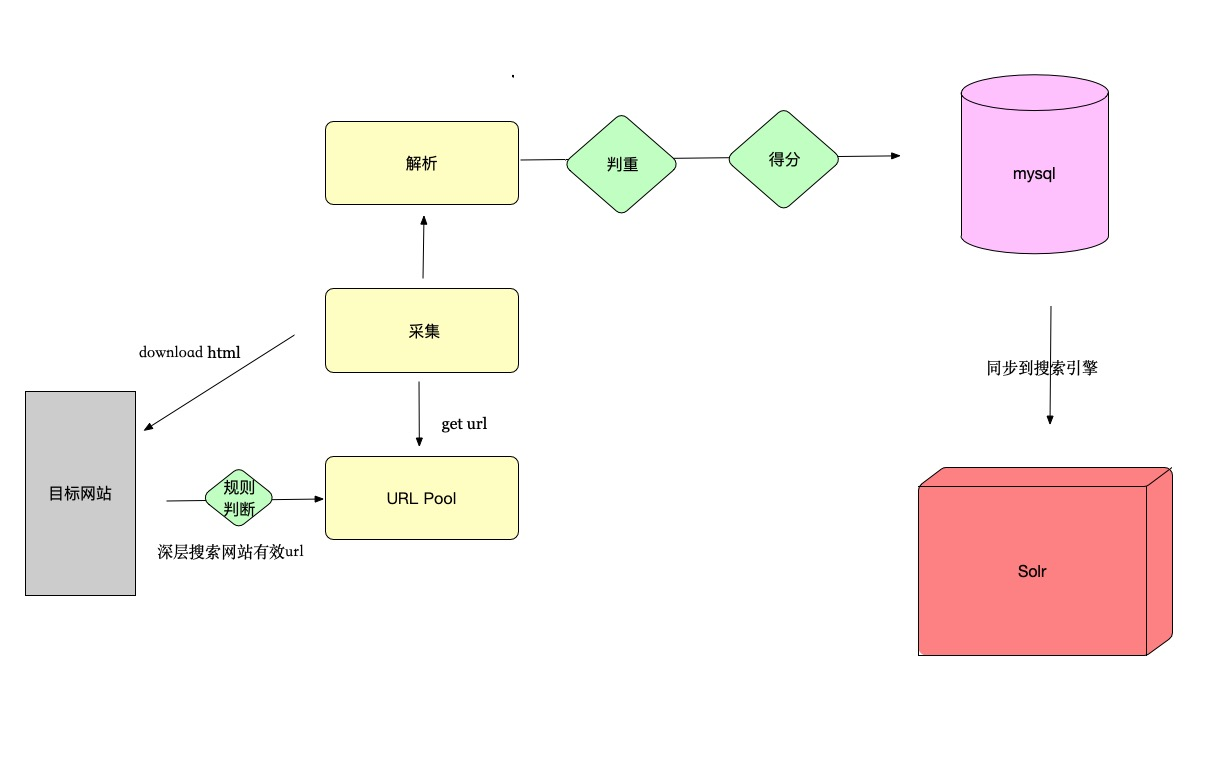
2.存储
mysql分库分表,按照时间和数量分成多个表 同步到solr搜索引擎
redis缓存热点数据 首页、热搜等
fastdfs小文件存储系统,快速写入,快速查询,索引定位,集成nginx访问,带缩略图功能
3.搜索
solr搜索 集成ansj文本分词 可做集群
4.热点算法
hadoop mapreduce 定时任务更新, 分词 vsm空间向量 访问量 评论 转发 收藏 形成最终分数
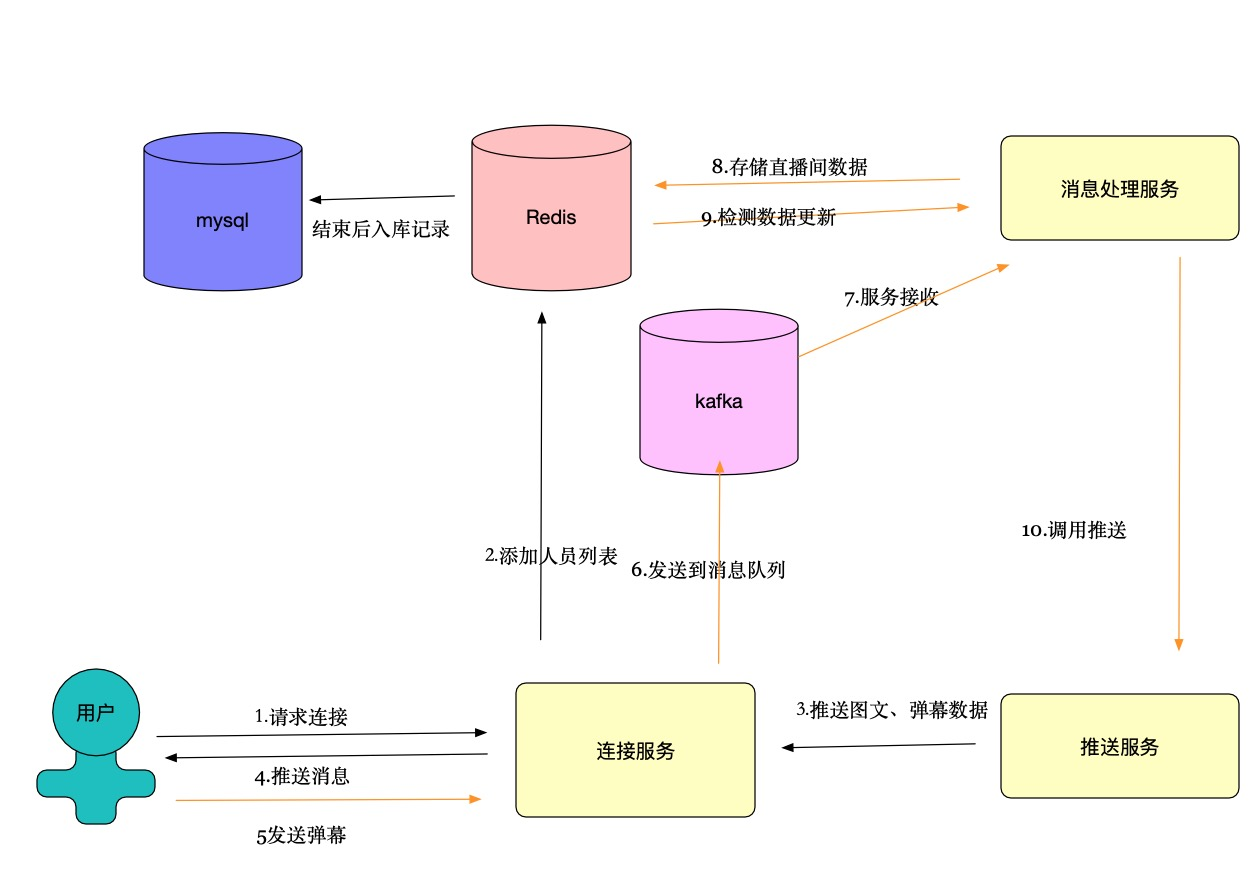
5.图文直播间
直播间内容redis主从同步,一主多从,aof快照备份,redis集群 基于内存存储快
websocket 动态扩容、缩减(根据服务器数量而定),根据连接数量自动连接对应的websocket服务,可以无限扩充,mysql neetty nio服务
支持短连接推送,a. 同时支持长连接和短连接,可根据路由服务的配置来决定;b. 自动降级,如果长连接同时三次连接不上,自动降级为短连接;c. 自动上报长连接性能数据;
心跳检测是否还在直播间,可短点重连
redis存储当前直播间连接人,记录连接服务位置、数量统计等功能
kafka接收用户发送的消息,作为数据缓冲,配置容灾队列
图文直播内容全量数据:mysql/mongodb 包括图文、弹幕、空投、用户列表
6.容灾备份
mysql定时binlog日志,可随时恢复
redis aof磁盘快照
kafka容灾队列
错误日志排查
轮询出错自动通知客户端修改轮询时间,客户端自动增大轮询时间
接口访问频率上限,恶意ip地址记录
7.调优
nginx做负载均衡、请求转发 (可以高并发连接、节省带宽、支持GZIP压缩、内存消耗少、稳定)
根据高频访问、评论、点赞文章自动训练词向量,设定文章热度分数
jvm gc调优
数据库调优:表结构设计 索引 查询语句 分库分表
数据分离:业务数据和历史数据分离、热点数据和全量数据分离
热点数据进入缓存
kafka异步削峰,消息推送 评论等
多线程处理任务
8.安全
centos系统
docker部署,各服务、组件互不干扰
可移植
依托阿里云,https连接,加密更加安全
系统权限设计,根据用户角色限定各页面、接口访问权限,依托加密token
9.代码规范
代码设计层级
代码注释
代码满足阿里巴巴开发规范要求
代码复用不冗余
代码接口文档